- Improve Reliability
Making Reliability Simple
Use a simple, proven framework
of just 4 Essential Elements to
create a Reliable Plant: - Online Training
Courses now Available in Multiple Languages!
Language barriers can hinder your team’s training and success. Click here to train them in their local language.
- Reliability Resources
Not sure yet?
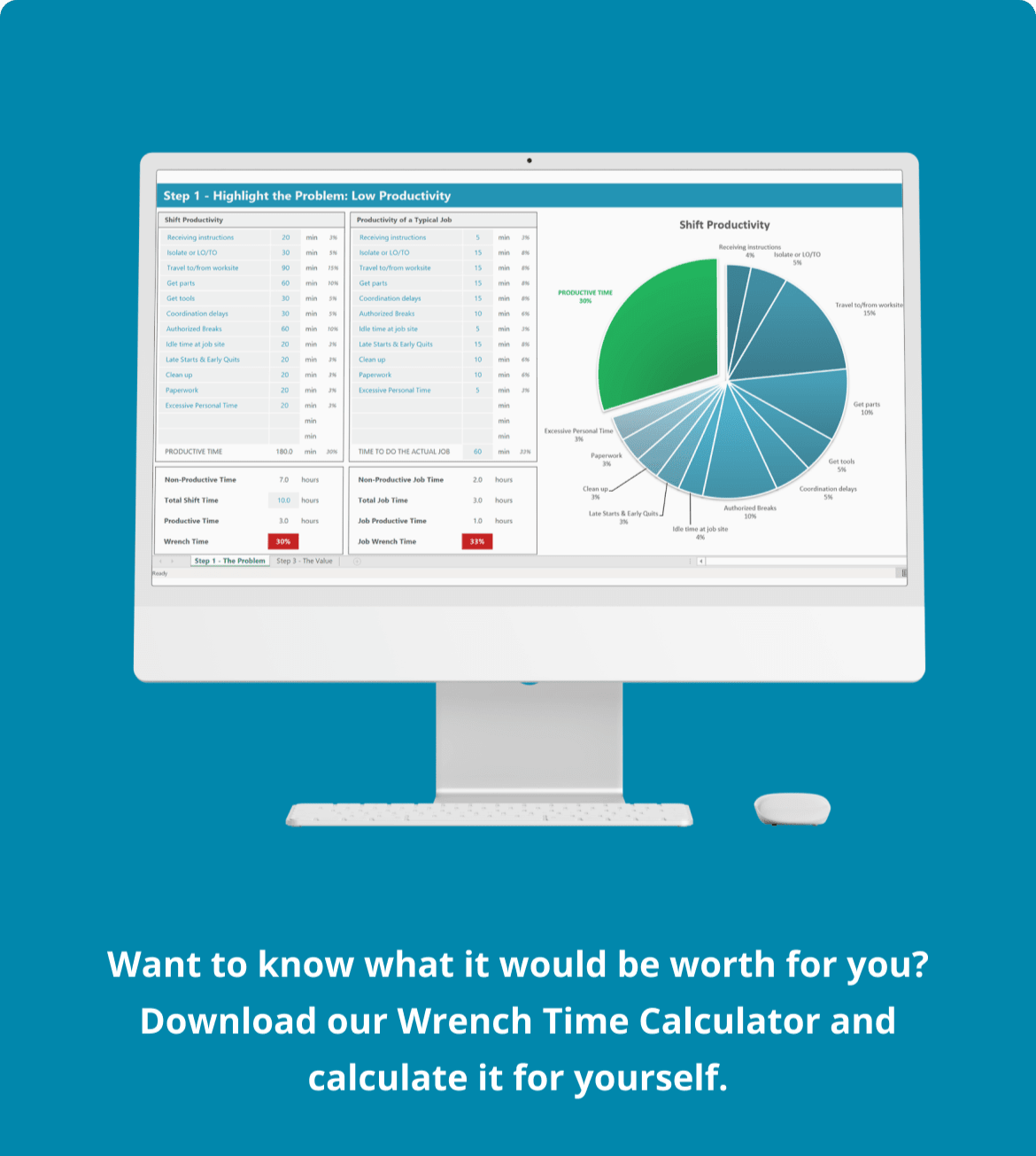
Want to better understand what we offer and how we can help? Check out our free tools in the resources section or download the framework:
- About us
- Contact us
- Login

- Improve Reliability
Making Reliability Simple
Use a simple, proven framework
of just 4 Essential Elements to
create a Reliable Plant: - Online Training
Courses now Available in Multiple Languages!
Language barriers can hinder your team’s training and success. Click here to train them in their local language.
- Reliability Resources
Not sure yet?
Want to better understand what we offer and how we can help? Check out our free tools in the resources section or download the framework:
- About Us
- Contact us
- Login
 Our Maintenance Planning & Scheduling Course is Now Available in
Our Maintenance Planning & Scheduling Course is Now Available in